微服务架构已成为构建复杂、可扩展和高性能应用程序的主流范式。它将单体应用分解为一组小型、独立的服务,每个服务围绕特定业务能力构建,并能够独立开发、部署和扩展。一个成功的微服务体系不仅需要清晰的架构蓝图,还需要精心选择的技术栈、可靠的服务治理机制以及高效的数据处理策略。
一、 微服务架构体系与核心蓝图
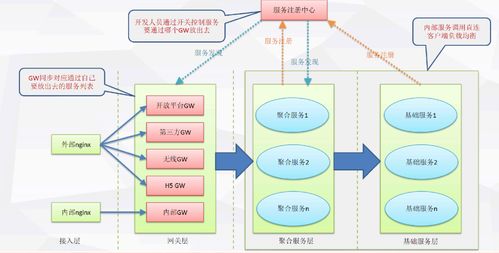
微服务架构的核心思想是“分而治之”。一个典型的体系通常包含以下几个关键层次与组件,可以通过架构图直观展示:
- 接入层:作为流量的统一入口,通常由API网关(如Kong, Zuul, Spring Cloud Gateway)承担。它负责路由、认证、限流、监控等跨领域关注点,是内部微服务对外的安全屏障。
- 微服务层:这是架构的核心,由众多独立的服务组成。每个服务:
- 自治:拥有独立的数据库(遵循数据库按服务拆分原则),独立的技术栈(可根据需求选择Java/Go/Python等)。
- 轻量通信:主要通过RESTful API或高性能的RPC(如gRPC)进行同步通信,或通过消息中间件(如Kafka, RabbitMQ)进行异步解耦。
- 服务注册与发现:服务实例启动时向服务注册中心(如Nacos, Eureka, Consul)注册,消费者从注册中心发现可用的服务实例,实现动态寻址。
- 支撑层:为微服务的稳定运行提供保障,包括:
- 配置中心(如Nacos, Apollo):统一管理所有服务的配置,实现动态更新。
- 分布式追踪与监控(如SkyWalking, Zipkin, Prometheus + Grafana):追踪请求链路,监控服务健康与性能指标。
- 熔断与限流(如Sentinel, Hystrix):防止服务雪崩,保障系统韧性。
- 基础设施层:基于容器化(Docker)和编排(Kubernetes)技术,实现服务的自动化部署、弹性伸缩和资源调度。
架构图直观地描绘了这些组件间的交互关系:用户请求经API网关路由至具体服务;服务间通过注册中心相互发现并通信;所有组件由统一的监控和配置体系管理,并运行在容器平台上。
二、 技术栈选型建议
技术栈的选择需平衡团队能力、业务需求和生态成熟度。一个常见的组合如下:
- 开发框架:Spring Boot / Spring Cloud(Java生态首选), Go Micro或Kratos(Go语言), Django或FastAPI(Python)。
- 服务注册与配置中心:Nacos(国产,功能全面), Consul(强一致性), Eureka(AP模型,已逐步淡出)。
- API网关:Spring Cloud Gateway(响应式,与Spring生态集成好), Kong(基于Nginx,性能强大)。
- 通信协议:内部高性能通信首选 gRPC(HTTP/2, Protocol Buffers);对外或简单场景使用 RESTful API。
- 消息中间件:Apache Kafka(高吞吐、日志场景), RabbitMQ(高可靠性,复杂路由)。
- 数据层:
- 数据库:按服务选择,如MySQL, PostgreSQL(关系型), MongoDB, Cassandra(NoSQL)。
- 缓存:Redis(几乎为标准选择)。
- 监控与追踪:Prometheus(指标收集)+ Grafana(可视化) + SkyWalking/Jeager(分布式追踪)。
- 容器与编排:Docker + Kubernetes(事实标准)。
三、 关键服务体系:治理与韧性
微服务的分布式特性带来了新的挑战,必须建立完善的服务治理体系:
- 服务治理:
- 服务发现与健康检查:确保流量只被路由到健康的实例。
- 负载均衡:在客户端(如通过Ribbon)或网关层实现流量合理分配。
- 流量管理:实现灰度发布、蓝绿部署、A/B测试等高级路由策略。
- 韧性设计:
- 熔断器模式:当下游服务故障率达到阈值时,自动熔断,避免资源耗尽,并预留降级逻辑。
- 舱壁隔离:利用线程池或信号量隔离资源,防止单一服务拖垮整个系统。
- 限流:在网关或服务入口控制QPS,保护后端服务。
- 重试与回退:为可能失败的远程调用设计有策略的重试和优雅回退。
四、 微服务下的数据处理挑战与策略
数据一致性是微服务架构中最复杂的问题之一,源于数据的私有化和分布式环境。
- 数据库设计:坚持“数据库按服务私有”原则。禁止服务直接访问其他服务的数据库,只能通过API交互。这确保了服务的松耦合和内聚性。
- 数据一致性模式:
- 强一致性(慎用):适用于对一致性要求极高的核心业务,可使用分布式事务解决方案,如Seata(AT/TCC模式),但性能损耗大。
- 最终一致性(主流):通过异步消息驱动数据同步,是更可扩展的选择。
- 事件驱动架构:服务在完成本地事务后,发布一个领域事件(如“订单已创建”)到消息队列。其他相关服务订阅该事件,并异步更新自己的数据。
- 事务性发件箱模式:将待发布的事件作为本地事务的一部分,与业务数据一同写入数据库的“发件箱”表。一个独立的“消息中继”进程轮询此表,将事件可靠地发布到消息队列。此模式保证了本地事务与事件发布的原子性。
- 事件溯源:不存储当前状态,而是存储导致状态变化的所有事件序列。通过重放事件可以重建任何时间点的状态,为复杂业务审计和回溯提供了强大支持。
3. 查询挑战与解决(CQRS):
微服务拆分后,跨多个服务的联合查询变得困难。命令查询职责分离模式应运而生。它将对数据的写操作(命令)和读操作(查询)分离。读服务可以拥有一个专为查询优化的数据视图(如从多个源服务同步数据形成的只读库,或使用Elasticsearch等搜索引擎),从而高效支持复杂查询,而无需干扰核心的写服务。
###
构建微服务架构是一个系统性工程,远不止于技术拆分。它始于清晰的架构蓝图和合理的技术选型,成于稳健的服务治理与韧性设计,并最终要妥善解决分布式数据管理的核心难题。采用事件驱动、最终一致性和CQRS等模式,可以在保持服务自治和可扩展性的有效管理数据。微服务不是银弹,它引入了复杂性,但通过完善的体系设计和工具支持,能够为快速变化、大规模的业务系统提供无与伦比的灵活性与韧性。